Grayscale to Hyperspectral at Any Resolution Using a Phase-Only Lens
Abstract
We consider the problem of reconstructing a H x W x 31 hyperspectral image from a H x W grayscale snapshot measurement that is captured using only a single diffractive optic and a filterless panchromatic photosensor. This problem is severely ill-posed, but we present the first model that produces high-quality results. We make efficient use of limited data by training a conditional denoising diffusion model that operates on small patches in a shift-invariant manner. During inference, we synchronize per-patch hyperspectral predictions using guidance derived from the optical point spread function. Surprisingly, our experiments reveal that patch sizes as small as the PSF’s support achieve excellent results, and they show that local optical cues are sufficient to capture full spectral information. Moreover, by drawing multiple samples, our model provides per-pixel uncertainty estimates that strongly correlate with reconstruction error. Our work lays the foundation for a new class of high-resolution snapshot hyperspectral imagers that are compact and light-efficient.
Hyperspectral Imaging via Camera Guided Diffusion
A diffractive metasurface lens introduces purposeful chromatic abberation, smearing the spectral information from a point in the scene across many pixels at the photosensor. This produces a simple but useful optical encoding of the high-dimensional hyperspectral cube (right) to a grayscale measurement (left). We show for the first time that the inverse, grayscale-to-hyperspectral reconstruction problem can be approximately solved without the need for complex multi-component optics or multiple measurements with spectral filters. The use of a simple lens and filterless sensor results in ambiguity where the grayscale measurement could map to many distinct but equally plausible hyperspectral cubes. Nonetheless, we obtain high quality reconstructions by leveraging a denoising diffusion model to learn the distribution of solutions.

We frame the reconstruction problem as a patch-to-patch translation task. We train our diffusion model to generate small 64x64x31 hyperspectral image patches, conditioned on 64x64 pixel measurement patches. This allows us to train with limited, real HSI datasets (900 images). Once trained, our model is applied to reconstruct measurements of any size. This is done by splitting the measurement into patches, processing all patches in parallel, and then enforcing consistency across patch predictions at each denoising step using diffusion guidance. Our guidance enforces that the stitched, full-size hyperspectral prediction projects back to the captured measurement when rendered with the camera's known optical response.
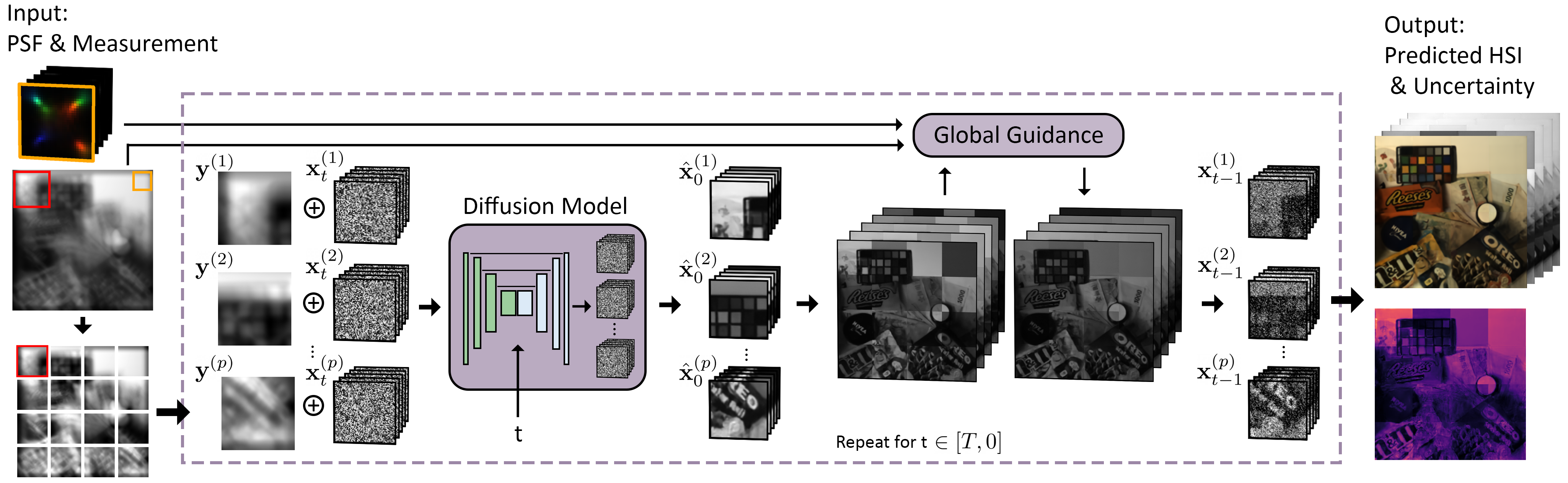
We note that the success in reconstructing hyperspectral images by processing the measurement in patches is initially surprising. The measurement is formed by a convolution with the spatially-extended point-spread function kernel. Consequently, relevant signal about a target HSI patch is partially scattered outside of the co-aligned measurement patch. In addition, extraneous signal from neighboring HSI patches is scattered into the measurement patch. This makes a patch-based reconstruction algorithm highly ill-posed. Despite this fact, we find that our patch model outperforms existing deep models that process full measurements directly. We show that there is value in concentrating neural capacities to smaller regions using a diffusion model and to instead synthesize full-size predictions by tying together the patch predictions using guidance.
In contrast to RGB diffusion models that denoise only three image channels, our hyperspectral diffusion model is trained to denoise 31 channels corresponding to the scene radiance on narrow-band wavelengths from 400 to 700 nm. Below we show the generated HSI reconstructions from our trained model, displayed for several wavelength channels as the sampling algorithm iterates through time. Since the predictions change with different initial noise seeds, we also generate an uncertainty map by computing the total spectral variation per-pixel after repeated draws. We find that our hyperspectral diffusion model produces accurate spectral reconstructions. The spectral channels highlight different features and objects in the scene and provides a deeper representation than RGB images.



HSI Reconstructions on the ARAD1K Dataset
We benchmark our algorithm against existing grayscale to hyperspectral reconstruction networks using the ARAD1K dataset. Although our patch-based model can handle measurement of any sizes, we first train/test on 256x256 pixel measurements to enable comparison with previous models that are limited to small images. In the paper, we demonstrate that our model can directly reconstruct larger 1280x1280 and 1280x1536 pixel measurements. Additional studies are discussed in the paper, considering RGB filters and different optics used to capture measurements.
In the sliders below, we show the rendered grayscale measurements that are used as conditioning for our diffusion model. Each measurement is simulated using the metasurface lens and has significant chromatic aberration. To reconstruct a prediction of the true hyperspectral images, each measurement is split into 16 64x64 pixel patches during inference time and processed in parallel. The reconstructed hyperspectral image is visualized projected to RGB colorspace. We are able to restore fine spatial features and dense spectral information for every pixel, using only simple optical cues.















Our work is the first to demonstrate that hyperspectral images can be restored from a grayscale measurement captured using a single, simple lens. Moreover, we found that no existing network can successfully solve this problem. We qualitatively display our findings below, showing the reconstructed hyperspectral images (viewed in RGB colorspace) reconstructed by our model vs previous networks.

High Resolution HSI Reconstruction on ICVL and Harvard Datasets
Here we highlight the unique ability of our model to process measurements of any size by splitting the measurement into smaller chunks. Our diffusion model only requires the memory and resources to process one 64x64 patch at any given moment. This enables high-resolution reconstructions on a commodity GPU. In contrast, most existing methods would attempt to reconstruct the full HSI at once, requiring significantly more memory and compute. A static view of select reconstructions is show below:
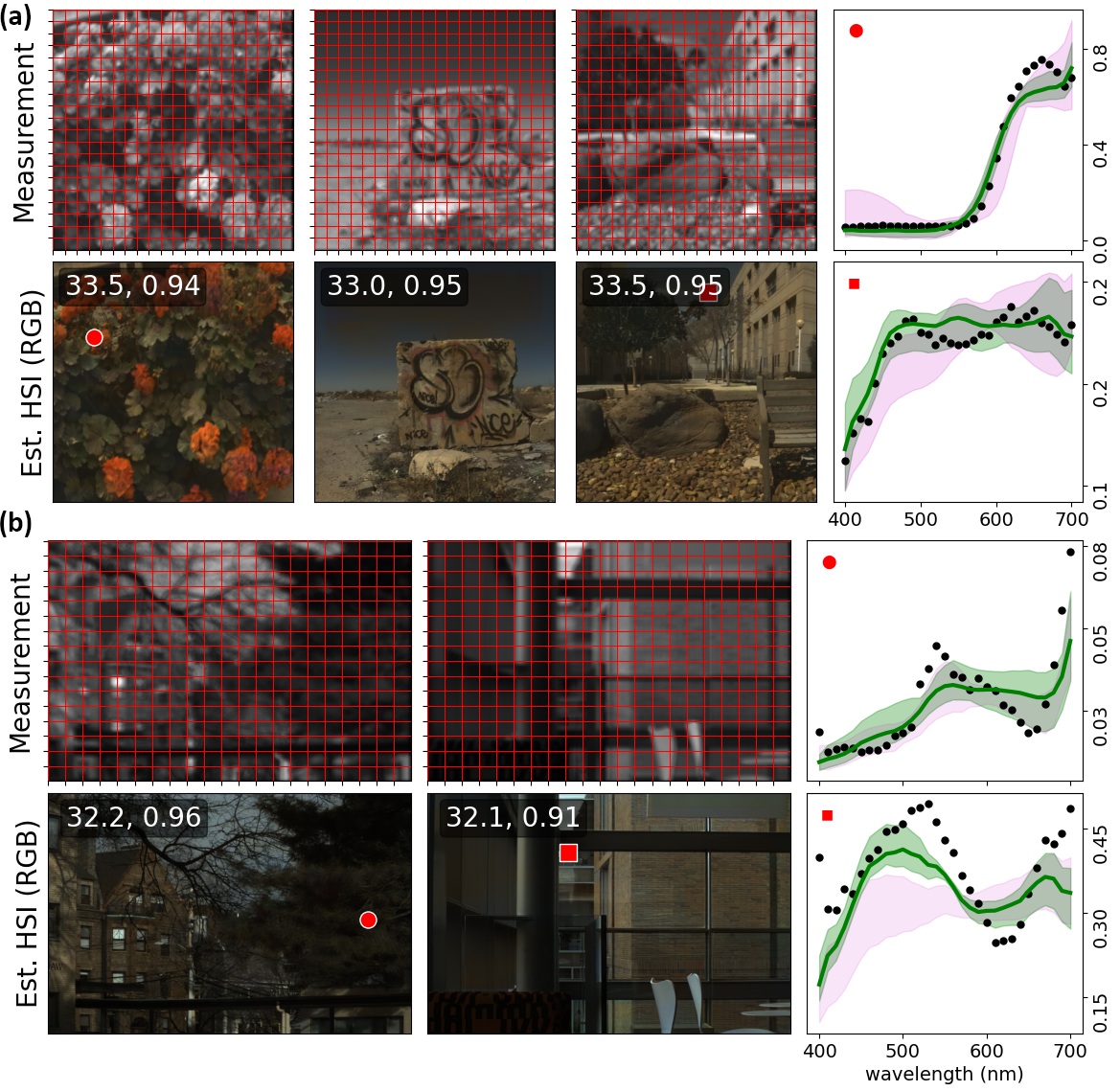
Below, we show an interactive display of two 1280x1280 resolution scenes from the ICVL dataset (this takes some time to load given that these are quite large!). The grayscale measurement is displayed in the left images (red grid denotes patches). The reconstructed HSI is viewed in RGB space in the middle and the line plot on the right shows the dense spectral curve for each highlighted pixel. We generally observe accurate spectral restorations for natural scenes without sacrificing FOV or resolution.